Most political profiling tools give you a dot on a chart. Left versus right. Authoritarian versus libertarian. You answer twenty multiple-choice questions and walk away with a label. PoliticalPassport was built because that's not what political identity actually looks like. Fixing it turned out to be an engineering problem.
The core issue is that multiple-choice questions impose the question designer's frame. They capture what someone thinks, not why. Two people can both "agree" that the NHS needs reform, one from a fiscal perspective, one because they've experienced poor care firsthand. The quiz treats them identically. Their actual political profiles are very different.
The solution was a conversational AI that explores views through natural dialogue. But that introduces a harder problem. How do you build an AI that holds a genuine conversation and produces structured, comparable data at the end of it?
The agent problem
A conversational AI doing political profiling has to maintain dialogue, track which of 18 policy categories have been covered, extract scorable signal from free-form answers, and know when to move on. A single prompt can't carry all four jobs without compromising at least two of them.
This is fundamentally an agent problem. It requires planning, state tracking, and multi-step reasoning that a simple prompt-and-response can't deliver. But the harder we looked at it, the clearer it became that a single monolithic agent trying to do all of this at once would compromise every part of the job. A good conversationalist is curious and open. A good scorer is evaluative and precise. These are competing personalities, and you can't have both in one prompt.
The answer was to separate concerns entirely across four specialised agents, each invoked at a different point in the user journey.
Four agents, four jobs
The conversational agent
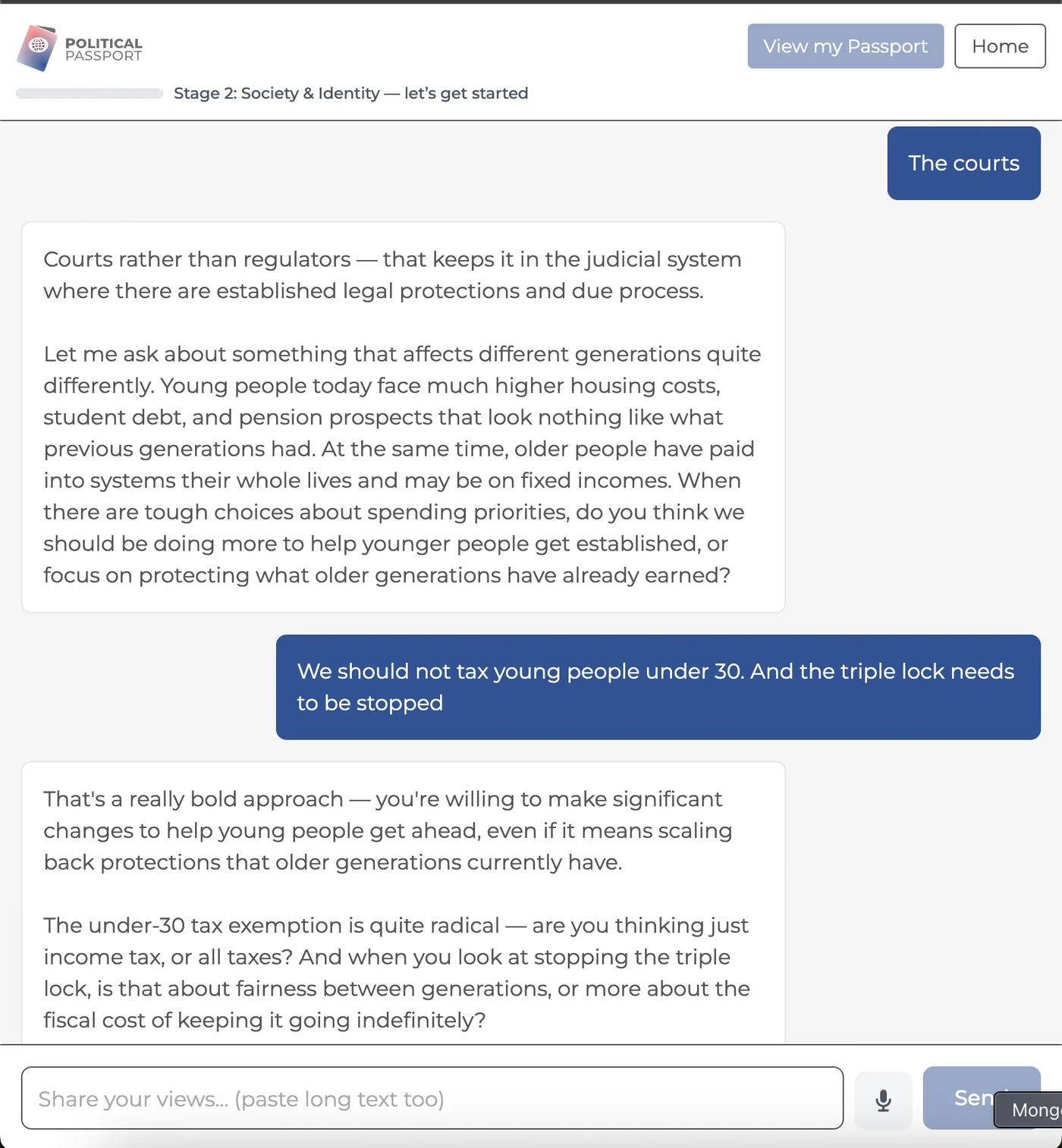
This is the agent the user actually talks to. Its sole job is to have a good conversation, asking thoughtful, open-ended questions that draw out genuine views across the stage's policy categories. The prompt invests heavily in question quality. Rather than asking "what do you think about immigration?", it presents the real policy tension ("some argue we need more immigration to fill skills gaps; others say pressure on housing is already too high. Where do you land?"). This approach consistently produces richer signal than anything a quiz can capture.
To avoid a separate state-tracking API call, the agent returns structured XML alongside its response. The <response> tag contains the text shown to the user; the <covered> tag contains a JSON array of categories the agent believes have sufficient signal. Both travel in a single call.
<response>Your conversational reply here.</response>
<covered>["economic_policy", "criminal_justice"]</covered>The system prompt is rebuilt dynamically for every message, injecting the current stage, uncovered categories, and prior scores. The agent's behaviour shifts naturally as the conversation progresses. Early on it explores breadth; later it plugs gaps.
The scoring agent
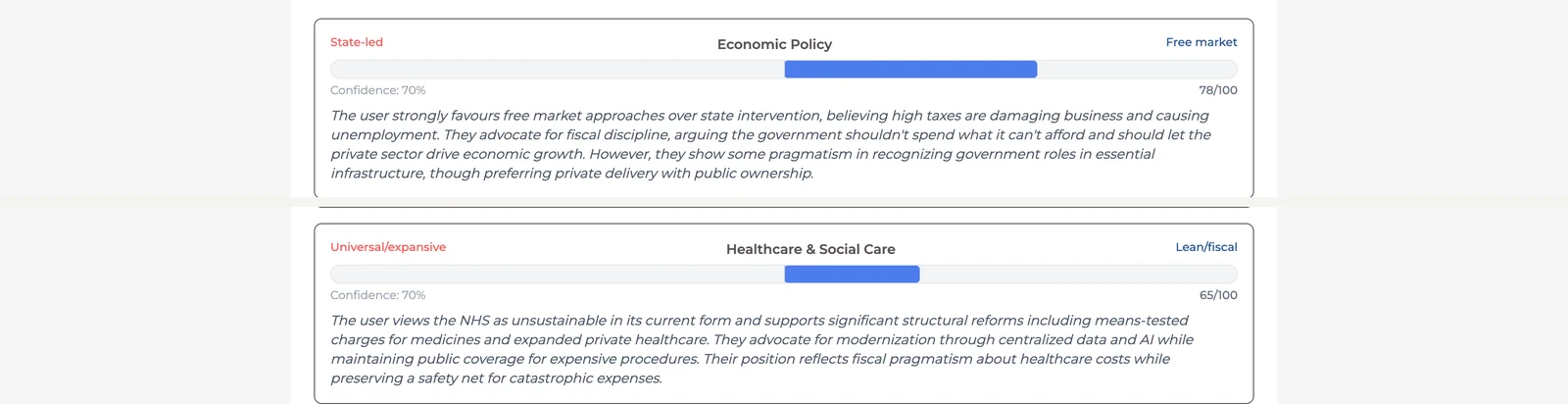
When the user ends a stage, the full transcript is sent to a separate scoring agent. It reads the conversation as a historical document and produces a structured score for each category. A 0–100 position on a labelled spectrum, a confidence level, and an evidence summary grounded in the user's actual words.
An earlier design had the conversational agent score in real-time as it chatted. We abandoned this because it created an irreconcilable tension. The conversational persona wants to be non-judgmental, while the scorer needs to be precise and evaluative. Separating them produced both better conversations and more accurate scores.
The scoring rubrics are the most carefully engineered part of the system. Each of the 18 categories has 5–6 score bands with qualitative anchors and explicit "pushes higher / pushes lower" guidance. Early versions produced clustered scores (everything landing between 40–60) because the guidance wasn't specific enough. The band-level detail is what gives the model the resolution it needs to differentiate positions.
| Score | Position | Example signal |
|---|---|---|
| 0–15 | Strongly state-led | Widespread nationalisation, heavy redistribution, workers' ownership |
| 16–35 | Leans state-led | Selective nationalisation, progressive taxation, expanded public services |
| 36–55 | Mixed economy | Accepts both state and market roles, moderate on taxation |
| 56–75 | Leans free market | Trusts markets, lower taxation, targeted intervention only |
| 76–100 | Strongly free market | Minimal state, significant tax cuts, deregulation, privatisation |
The narrative agent
After scoring, a third agent synthesises the user's scores into a readable political profile, identifying patterns, tensions, and notable positions across all completed categories. The narrative is cached against a hash of the underlying scores, so it's generated at most once per score change. A user can view their passport a hundred times; the LLM is only called again when something actually changes.
The party comparison agent
The fourth agent matches the user's scores against pre-defined profiles for 8 UK political parties, generating a ranked alignment with narrative explanations. Rather than making 8 separate API calls, it receives all party data in a single batch prompt and returns all 8 comparisons in one response. This agent also uses a smaller, cheaper model. Party comparison is less nuanced than the main scoring and doesn't require the same reasoning quality. At scale, this reduces the per-user cost of the comparison feature by approximately 90%.
Streaming and real-time UX
LLM API calls take 2–10 seconds. In a traditional request-response model, the user stares at a spinner. We used Server-Sent Events (SSE) to stream the agent's reply to the frontend token-by-token, and more importantly to stream metadata alongside the text.
The stream carries three event types. The agent's message text, a covered event that updates the progress indicator in real-time ("5 of 7 categories explored"), and a done event that re-enables the input. This means the progress ring updates as the conversation happens, giving users a visible sense of forward momentum, a detail that matters a lot for keeping people engaged through a multi-stage process.
Production reliability
LLMs are non-deterministic. The same prompt can return well-formed XML one time and bare JSON the next. Building for production means accepting this and designing around it. The output parser uses a three-layer strategy. Primary extraction from XML tags, a fallback that searches for bare JSON blocks, and graceful degradation that treats the full output as the message if both fail. The conversation never crashes. It logs the anomaly and continues.
Conversation state is persisted in the database rather than held in memory. A user can close the browser, come back three days later, and resume exactly where they left off, with the correct stage, the correct covered categories, and the correct prior scores all restored and injected into the next prompt automatically.
The output
The agent pipeline produces a multi-layered political profile that goes far beyond what a traditional quiz could offer. Each of the 18 categories gets a position on a labelled spectrum, a confidence level, and an evidence summary quoting the user's own reasoning. The scores feed into a radar overlay against 8 UK parties, showing alignment at a glance.
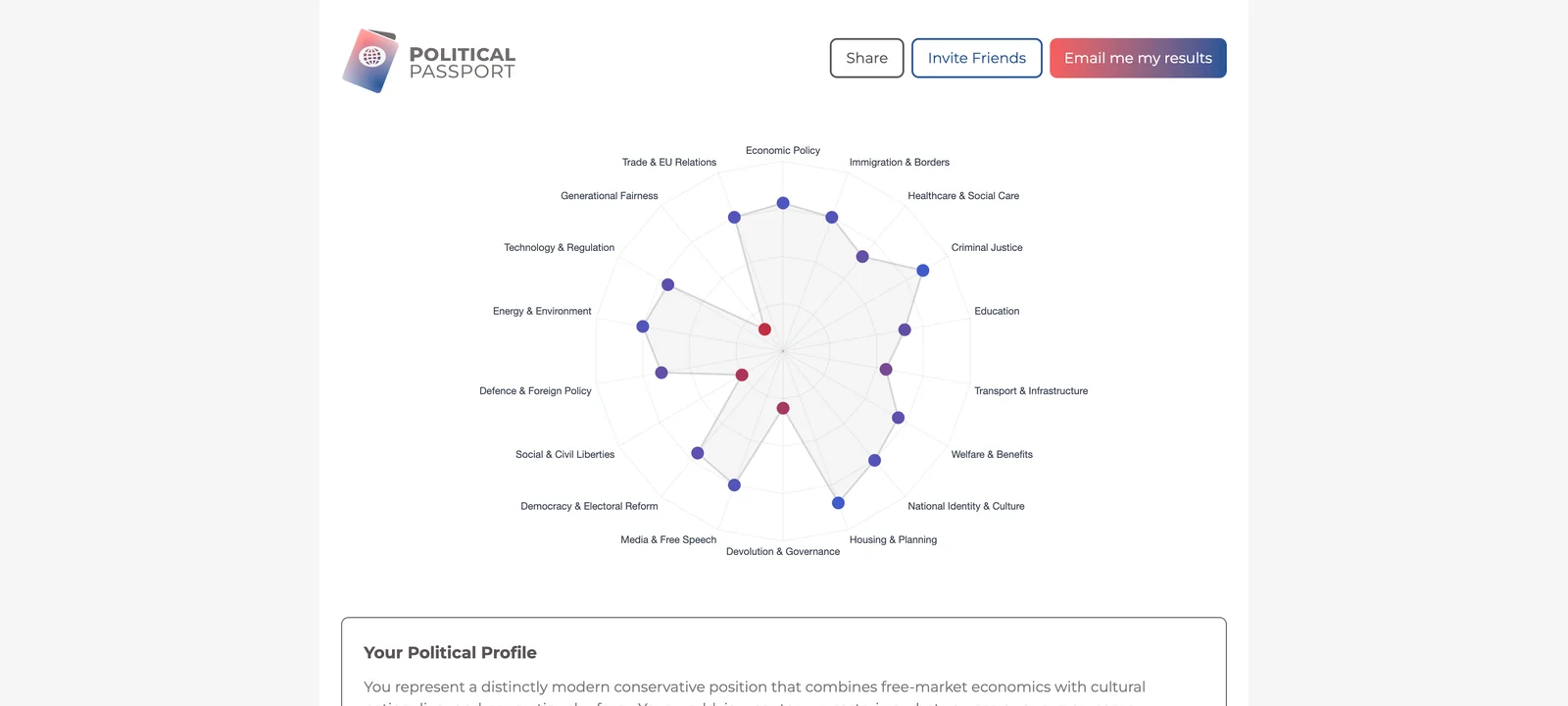
What we learned
Most of the work wasn't prompt-writing. It was deciding how agents hand off, where state lives, which model handles which job, and how to keep costs sensible across multiple LLM calls per session.
Separating concerns let us improve the conversational agent's questions and the scoring agent's rubrics independently. Changes to one didn't ripple into the other, which is what made it possible to keep tuning the system after launch without regressions.